CoroutineContext 前面我们了解了Kotlin协程的使用方式以及一些注意的点,但我们并没有具体查看它的实现细节以及原理。我们知道切换协程执行的线程可以使用Dispatchers,我们知道一个协程的引用是一个Job,我们也知道协程中遇到异常需要使用CoroutineExceptionHandler,如果我们仔细观察它们的父类,最终可以发现它们都继承自CoroutineContext。CoroutineContext被称为协程上下文,他是一种独特的结构,除了本身的上下文以外,它还是一种类似Map的结构,本文主要分析其结构的组成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public interface CoroutineContext {public operator fun <E : Element> get (key: Key <E >) public fun <R> fold (initial: R , operation: (R , Element ) -> R ) public operator fun plus (context: CoroutineContext ) if (context === EmptyCoroutineContext) this else this ) { acc, element ->val removed = acc.minusKey(element.key)if (removed === EmptyCoroutineContext) element else {val interceptor = removed[ContinuationInterceptor]if (interceptor == null ) CombinedContext(removed, element) else {val left = removed.minusKey(ContinuationInterceptor)if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else public fun minusKey (key: Key <*>) public interface Key <E : Element >public interface Element : CoroutineContext {public val key: Key<*>public override operator fun <E : Element> get (key: Key <E >) @Suppress("UNCHECKED_CAST" ) if (this .key == key) this as E else null public override fun <R> fold (initial: R , operation: (R , Element ) -> R ) this )public override fun minusKey (key: Key <*>) if (this .key == key) EmptyCoroutineContext else this
上面是CoroutineContext的定义,从定义我们也可以看出,它本身是属于一个集合类型的定义,它实现了三个重要方法,分别是添加、获取以及查询,刚好是集合最重要的三个方法。为什么说它是类似Map结构呢?这是从它的具体实现Element看出来的,每个Element中有一个Key,这是用于明确标识当前Element属性的键。get方法:
1 2 3 public override operator fun <E : Element> get (key: Key <E >) @Suppress("UNCHECKED_CAST" ) if (this .key == key) this as E else null
该方法是在Element中实现的,根据key进行比对,相同则返回本身,否则返回null,同时它还是操作符重载方法,因此我们不仅可以通过context.get(key)的方式获取Element,还能直接使用context[key]的简化方式。fold:
1 2 public override fun <R> fold (initial: R , operation: (R , Element ) -> R ) this )
同样也是在Element中实现的,但它并没有实现细节,直接执行了其第二个参数,将第一个参数作为表达式的参数传递进来的,因此该方法的实现细节是在表达式中。minusKey方法,根据Key删除某个Element:
1 2 public override fun minusKey (key: Key <*>) if (this .key == key) EmptyCoroutineContext else this
查询和删除都是针对于本身的,即只和本身做对比,好像并没有看出来集合结构,所以接下来我们继续看添加的方法,看它是如何添加上下文的。 也就是plus方法,同样这也是一个重载方法,实现了该方法后我们就可以直接通过+操作符来将两个上下文相加:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public operator fun plus (context: CoroutineContext ) if (context === EmptyCoroutineContext) this else this ) { acc, element ->val removed = acc.minusKey(element.key)if (removed === EmptyCoroutineContext) element else {val interceptor = removed[ContinuationInterceptor]if (interceptor == null ) CombinedContext(removed, element) else {val left = removed.minusKey(ContinuationInterceptor)if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
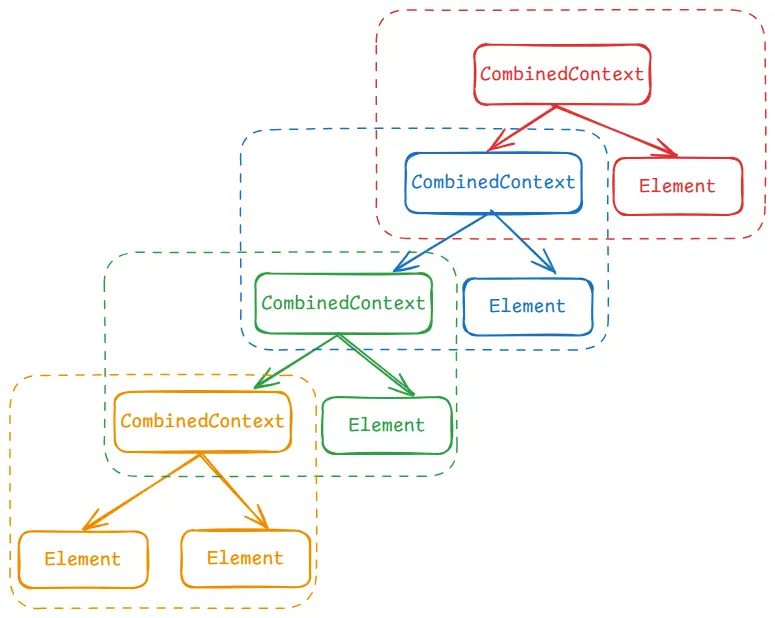
该方法是直接在CoroutineContext中实现的,这里的逻辑整体理一下,就是如果要添加的context的key已经存在了,则会删除掉老的context并替换成新的。替换后通过CombinedContext将两个上下文结合起来,如果上下文中存在拦截器,则将拦截器上下文移出放在最顶层。CombinedContext本身也是一个上下文,它的主要作用就是将两个上下文进行结合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 internal class CombinedContext (private val left: CoroutineContext,private val element: Elementoverride fun <E : Element> get (key: Key <E >) var cur = this while (true ) {return it }val next = cur.leftif (next is CombinedContext) {else {return next[key]public override fun <R> fold (initial: R , operation: (R , Element ) -> R ) public override fun minusKey (key: Key <*>) return left }val newLeft = left.minusKey(key)return when {this else -> CombinedContext(newLeft, element)
所以,CombinedContext本身也是一个协程上下文的实现者,只是它的作用是来将多个上下文结合起来,因此说CoroutineContext本身除了上下文的作用外,还属于Map类型的集合结构。整体结构如下:Map结构,同时相同Key的上下文只能单个存在,例如我们获取协程名称可以通过coroutineContext[CoroutineName]来获取。
1 2 3 4 5 6 7 8 9 10 11 12 public abstract class AbstractCoroutineContextElement (public override val key: Key<*>) : Elementpublic data class CoroutineName (val name: Stringpublic companion object Key : CoroutineContext.Key<CoroutineName>override fun toString () "CoroutineName($name )"
CoroutineName也是一种上下文,但是它实际作用就是一个标签作用,它继承自AbstractCoroutineContextElement,其中key的值是CoroutineName。注意这是一种缩写方式,因为CoroutineName中添加了一个伴生类Key,而我们知道在Kotlin中课可以直接用类名引用到伴生对象,所以才能这样写。CoroutineName.Key,并且在获取的时候也通过coroutineContext[CoroutineName.Key]来获取,只是通过伴生对象简化了而已,并不是传递的类名作为Key的。因此,后续如果我们也需要自定义上下文时,也可以通过这种方式去自定义Key。
1 2 3 4 5 6 7 class MyCoroutineContext (val name: Stirngcompanion object : CoroutineContext.Key<MyCoroutineContext>
最后还有一个EmptyCoroutineContext表示的空上下文,实际是个单例对象,本身并没有任何实现,它存在的意义就是避免直接返回null,让协程上下文至少存在一个上下文。
1 2 3 4 5 6 7 8 9 10 11 public object EmptyCoroutineContext : CoroutineContext, Serializable {private const val serialVersionUID: Long = 0 private fun readResolve () public override fun <E : Element> get (key: Key <E >) null public override fun <R> fold (initial: R , operation: (R , Element ) -> R ) public override fun plus (context: CoroutineContext ) public override fun minusKey (key: Key <*>) this public override fun hashCode () Int = 0 public override fun toString () "EmptyCoroutineContext"
其所涉及的多个结构均是直接或间接实现了CoroutineContext,因此不需要额外的对象来进行引用,直接使用本身即可表示元素又可表示集合,他们的类图如下:
总结 到这里基本上协程上下文的结构就已经清晰了,它本身使用CombinedContext将多个上下文结合起来,通过Key来进行区分。因此它本身就可以作为一个Map结构的集合,每次添加上下文实际上就是在自身上面继续包一层CombinedContext,因此添加的上下文越多,它本身的结构层级实际越深。